
SQL group by is one of the most commonly used statements you will come across and it has many different applications.
It is a great way to aggregate data, when you are using one of the following in the select statement:
(A) Sum
(B)Count
(C) Average
(D) Max
(E) Min
There are more that can be added to this list , we just gave you some examples.
So lets look at some areas where it might be applied. We will use the below tables from our database to apply the group by to:
CUSTOMER
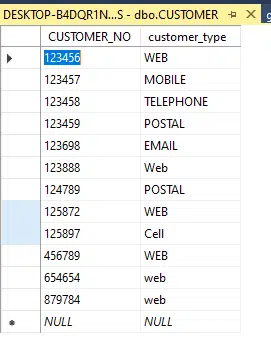
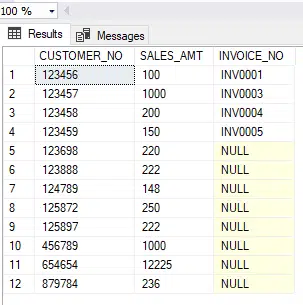
SALES
Group by using count
In the below code we are applying a very straight forward group by, and it is on the customer_type column.
To make the output easier to follow, we have also applied an alias to the count column. This makes it easier to see the output.
Also this column is not stored in the database, so you would need to apply additional logic to accomplish the storage of that data.
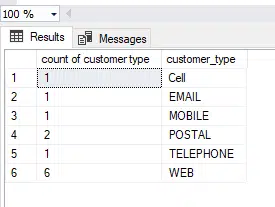
select count(customer_type) as "count of customer type",customer_type from dbo.CUSTOMER group by customer_type;
Giving output:
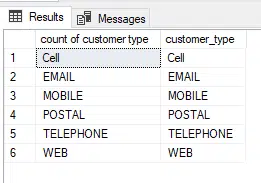
If we remove the count from the above SQL, it simply will show the below output:
Group by using joins
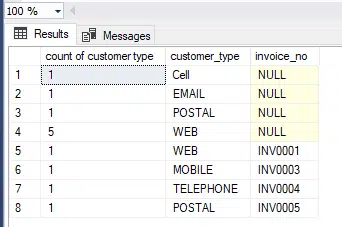
Here we are joining tables, and then using a group by. It is quite similar to the first query, but it now brings in additional information, namely the invoice_no.
In addition now the data has better meaning. For example in the group by using count above , the row 6 had six values for WEB.
Now that line is broken out further , as one of the WEB records has an invoice value, it provides a better understanding of the data.
select count(a.customer_type) as "count of customer type",a.customer_type,b.invoice_no from dbo.CUSTOMER a --left table left join dbo.SALES b --right table on a.customer_no = b.customer_no --where b.invoice_no is null group by a.customer_type,b.invoice_no
Giving output:
Group by including case statements
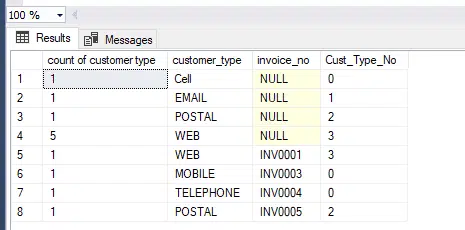
In the next scenario, we will see how to use case statements in SQL.
The inclusion will allow additional information to be included in the output.
As can be seen the group by is not impacted by this, but the good thing is that if you are building a machine learning model, this will include great additional information.
select count(a.customer_type) as "count of customer type",a.customer_type,b.invoice_no, case when a.customer_type = 'EMAIL' then 1 when a.customer_type = 'POSTAL' then 2 when a.customer_type = 'WEB' then 3 ELSE 0 end as Cust_Type_No from dbo.CUSTOMER a --left table left join dbo.SALES b --right table on a.customer_no = b.customer_no group by a.customer_type,b.invoice_no
Which will give:
Group by using a sub query
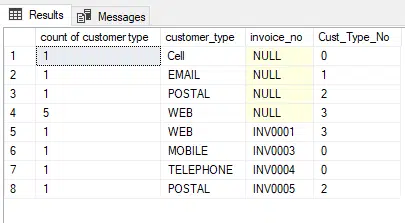
The final approach that we will look at is where you are using a sub query.
The purpose of a subquery is to get the information you want, and then you can pick data out of it as you see fit.
In the below SQL we can see that aggregates further the count of the fields. If we ran the subquery on its own, then we would get:
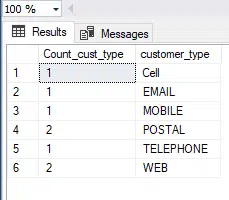
But running the below now aggregates up further, it essentially is counting the no of occurences of each value in the “Cust_Type_No” column.
Then it adds beside for each, the values that are associated with it from the customer_type column.
select count(tmp.Cust_Type_No) as "Count_cust_type", tmp.customer_type from ( select count(a.customer_type) as "count of customer type",a.customer_type,b.invoice_no, case when a.customer_type = 'EMAIL' then 1 when a.customer_type = 'POSTAL' then 2 when a.customer_type = 'WEB' then 3 ELSE 0 end as Cust_Type_No from dbo.CUSTOMER a --left table left join dbo.SALES b --right table on a.customer_no = b.customer_no group by a.customer_type,b.invoice_no) as tmp group by tmp.Cust_Type_No,tmp.customer_type
The output which is:
So in summary here are some points to look out for:
(A) Use group by with the right aggregate function, so you get the right output.
(B) You can add in additional logic without impacting the group by, examples here include case statements.
(C) Group by can be added to sub queries as well as the main query you are extracting data from.
See other posts that may interest you!
how to write subqueries in sql