
Estimated reading time: 5 minutes
In our previous post on how to compare CSV files for differences we showed how you could see the differences, but what if you wanted to see if a record was 100% matched or not?
Here we are going to use SequenceMatcher which is a python class that allows you to compare files and return if they are matched as a percentage.
Let’s look at the code
Import statements and read in the CSV files. Here we do the usual of importing the libraries we need and read in the two CSV files we use:
Note we also set up the data frame settings here as well, so we can see the data frame properly. See further down.
import pandas as pd
import numpy as np
import math
from difflib import SequenceMatcher
pd.set_option('max_columns', None)
pd.set_option('display.width', None)
#Read in the CSV files
df1 = pd.read_csv('CSV1.csv')
df2 = pd.read_csv('CSV2.csv')The two CSV files look like this:
CSV1
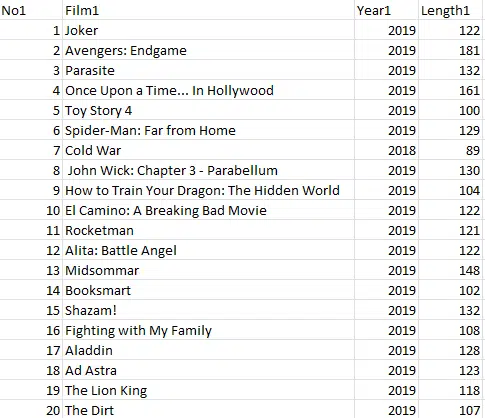
CSV2

Next, we are going to create an array. Creating an array allows the comparison to be completed as it creates indexes, and the indexes in each array can be compared and then the percentage difference can be calculated.
#Create an array for both dataframes
array1 = np.array(df1)
array2 = np.array(df2)Our next step is to transfer the arrays to a data frame, change all integer values to a string, and then join both data frames into one.
In this instance the changing of values into a string allows those values to be iterated over, otherwise, you will get an error ” TypeError: ‘int’ object is not iterable“
#Transfer the arrays to a dataframe
df_CSV_1 = pd.DataFrame(array1, columns=['No1','Film1','Year1','Length1'])
df_CSV_2 = pd.DataFrame(array2, columns=['No2','Film2','Year2','Length2'])
#Change all the values to a string, as numbers cannot be iterated over.
df_CSV_1['Year1'] = df_CSV_1['Year1'].astype('str')
df_CSV_2['Year2'] = df_CSV_2['Year2'].astype('str')
df_CSV_1['Length1'] = df_CSV_1['Length1'].astype('str')
df_CSV_2['Length2'] = df_CSV_2['Length2'].astype('str')
#join the dataframes
df = pd.concat([df_CSV_1,df_CSV_2], axis=1)We are now moving to the main part of the program, which gives us the answers we need. Here we create a function that does the calculations for us:
#Create a function to calculate the differences and show as a ratio.
def create_ratio(df, columna, columnb):
return SequenceMatcher(None,df[columna],df[columnb]).ratio()
Next we calculate the differences and format the output
#Here we use apply which will pull in the data that needs to be passed to the fuction above.
df['Film_comp'] = df.apply(create_ratio,args=('Film1','Film2'),axis=1)
df['Year_comp'] = df.apply(create_ratio,args=('Year1','Year2'),axis=1)
df['Length_comp'] = df.apply(create_ratio,args=('Length1','Length2'),axis=1)
#This creates the values we are looking for
df['Film_comp'] = round(df['Film_comp'].astype('float'),2)*100
df['Year_comp'] = round(df['Year_comp'].astype('float'),2)*100
df['Length_comp'] = round(df['Length_comp'].astype('float'),2)*100
#this removes the decimal point that is added as a result of using the datatype 'Float'
df['Film_comp'] = df['Film_comp'].astype('int')
df['Year_comp'] = df['Year_comp'].astype('int')
df['Length_comp'] = df['Length_comp'].astype('int')
#Print the output
print(df)And the final output looks like this:
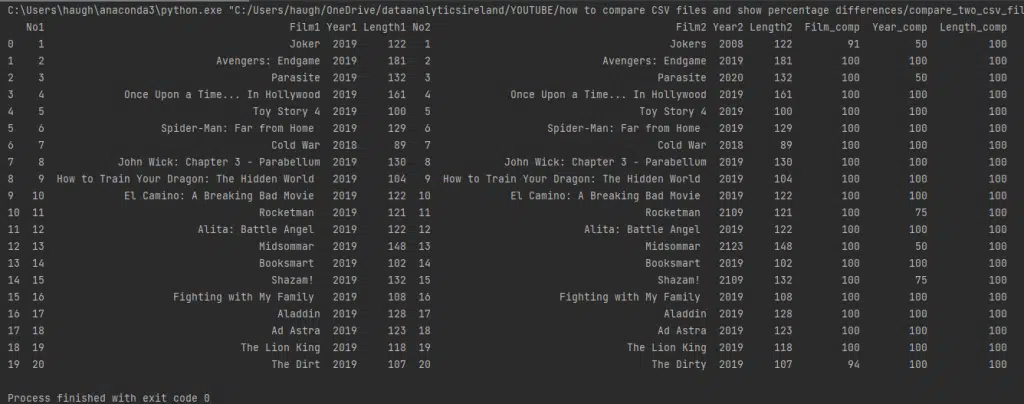
An explanation of the output
As can be seen, the last three columns are the percentages of the match obtained, with 100 been an exact match.
For index value 1 there is Joker in the first file, but Jokers is in the second file.
The ratio is calculated as follows:
Joker is length 5, Jokers is length 6 = 11 characters in length
So the logic looks at the sequence, iterating through the sequence it can see that the first 10 characters are in the same order, but the 11th character is not, as a result, it calculates the following:
(10/11) * 100 = 90.90
Finally, the round function sets the value we are looking for to 91.
On the same line, we shall compare the year:
2019 and 2008 are a total of eight characters.
In the sequence, the first two of each match, and as they are also found, give us four, and the ratio is as follows:
4/8 *100 = 50
For Index 20 we also compared the film name, in total there are 17 characters, but the program ignores what they call junk, so the space is not included, for that reason the ratio only calculates over sixteen characters.
In order to understand this better I have compiled the below:
| Index 1 | Index 1 | ||||||
| 2019 | 2008 | 8 | Joker | Jokers | 11 | ||
| 2 | Correct Spot | 1 | J | Correct Spot | 1 | ||
| 0 | Correct Spot | 1 | o | Correct Spot | 1 | ||
| 1 | Incorrect spot | 0 | K | Correct Spot | 1 | ||
| 9 | Incorrect spot | 0 | e | Correct Spot | 1 | ||
| r | Correct Spot | 1 | |||||
| 2 | Found | 1 | J | Found | 1 | ||
| 0 | Found | 1 | o | Found | 1 | ||
| 1 | Found | 0 | K | Found | 1 | ||
| 9 | Found | 0 | e | Found | 1 | ||
| r | Found | 1 | |||||
| Total in Comparison | 8 | Total in Comparison | 11 | ||||
| Ratio | 0.50 | Ratio | 0.91 | ||||
| Index 20 | |||||||
| The Dirt | The Dirty | 16 | |||||
| T | Correct Spot | 1 | |||||
| H | Correct Spot | 1 | |||||
| E | Correct Spot | 1 | |||||
| Correct Spot | 1 | ||||||
| T | Found | 1 | |||||
| H | Found | 1 | |||||
| E | Found | 1 | |||||
| D | Correct Spot | 1 | |||||
| I | Correct Spot | 1 | |||||
| R | Correct Spot | 1 | |||||
| T | Correct Spot | 1 | |||||
| D | Found | 1 | |||||
| I | Found | 1 | |||||
| R | Found | 1 | |||||
| T | Found | 1 | |||||
| Total in Comparison | 16 | ||||||
| Ratio | 0.94 |