
Estimated reading time: 3 minutes
So you have numerous different automation projects in Python. In order to ensure a clean and smooth straight-through processing, checks need to be made to ensure what was received is in the right format.
Most but not all files used in an automated process will be in the CSV format. It is important there that the column headers in these files are correct so you can process the file correctly.
This ensures a rigorous process that has errors limited.
How to compare the headers
The first step would be to load the data into a Pandas data frame:
import pandas as pd
df = pd.read_csv("csv_import.csv") #===> Include the headers
print(df)The actual original file is as follows:
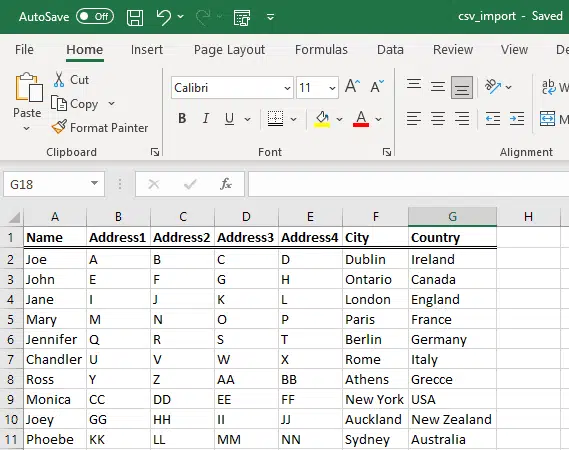
Next we need to make sure that we have a list that we can compare to:
header_list = ['Name','Address_1','Address_2','Address_3','Address_4','City','Country']
The next step will allow us to save the headers imported in the file to a variable:
import_headers = df.axes[1] #==> 1 is to identify columns
print(import_headers)
Note that the axis chosen was 1, and this is what Python recognises as the column axes.
Finally we will apply a loop as follows:
a = [i for i in import_headers if i not in header_list]
print(a)
In this loop, the variable “a” is taking the value “i” which represents each value in the import_headers variable and through a loop checks each one against the header_list to see if it is in it.
It then prints out the values not found.
Pulling this all together gives:
import pandas as pd
df = pd.read_csv("csv_import.csv") #===> Include the headers
print(df)
#Expected values to receive in CSV file
header_list = ['Name','Address_1','Address_2','Address_3','Address_4','City','Country']
import_headers = df.axes[1] #==> 1 is to identify columns
print(import_headers)
a = [i for i in import_headers if i not in header_list]
print(a)
Resulting in the following output:
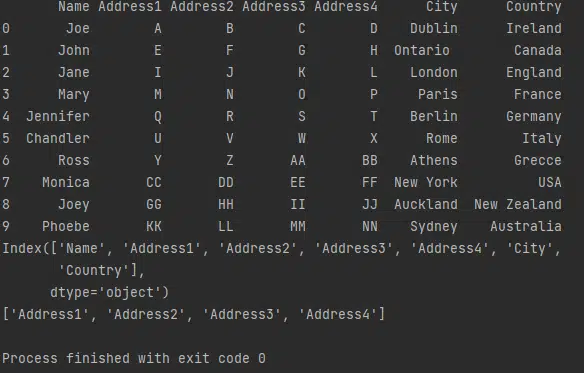
As can be seen the addresses below where found not to be valid, as they where not contained within our check list “header_list”
