
So you are working on a number of different data analytics projects, and as part of some of them, you are bringing data in from a CSV file.
One area you may want to look at is How to Compare Column Headers in CSV to a List in Python, but that could be coupled with this outputs of this post.
As part of the process if you are manipulating this data, you need to ensure that all of it was loaded without failure.
With this in mind, we will look to help you with a possible automation task to ensure that:
(A) All rows and columns are totalled on loading of a CSV file.
(B) As part of the process, if the same dataset is exported, the total on the export can be counted.
(C) This ensures that all the required table rows and columns are always available.
Python Code that will help you with this
So in the below code, there are a number of things to look at.
Lets look at the CSV file we will read in:
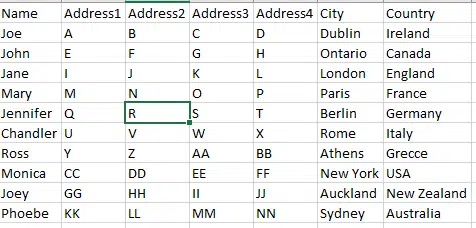
In total there are ten rows with data. The top row is not included in the count as it is deemed a header row. There are also seven columns.
This first bit just reads in the data, and it automatically skips the header row.
import pandas as pd
df = pd.read_csv("csv_import.csv") #===> reads in all the rows, but skips the first one as it is a header.
Output with first line used:
Number of Rows: 10
Number of Columns: 7
Next it creates two variables that count the no of rows and columns and prints them out.
Note it used the df.axes to tell python to not look at the individual cells.
total_rows=len(df.axes[0]) #===> Axes of 0 is for a row
total_cols=len(df.axes[1]) #===> Axes of 1 is for a column
print("Number of Rows: "+str(total_rows))
print("Number of Columns: "+str(total_cols))And bringing it all together
import pandas as pd
df = pd.read_csv("csv_import.csv") #===> reads in all the rows, but skips the first one as it is a header.
total_rows=len(df.axes[0]) #===> Axes of 0 is for a row
total_cols=len(df.axes[1]) #===> Axes of 0 is for a column
print("Number of Rows: "+str(total_rows))
print("Number of Columns: "+str(total_cols))
Output:
Number of Rows: 10
Number of Columns: 7
In summary, this would be very useful if you are trying to reduce the amount of manual effort in checking the population of a file.
As a result it would help with:
(A) Scripts that process data doesn’t remove rows or columns unnecessarily.
(B) Batch runs who know the size of a dataset in advance of processing can make sure they have the data they need.
(C) Control logs – databases can store this data to show that what was processed is correct.
(D) Where an automated run has to be paused, this can help with identifying the problem and then quickly fixing.
(E) Finally if you are receiving agreed data from a third party it can be used to alert them of too much or too little information was received.